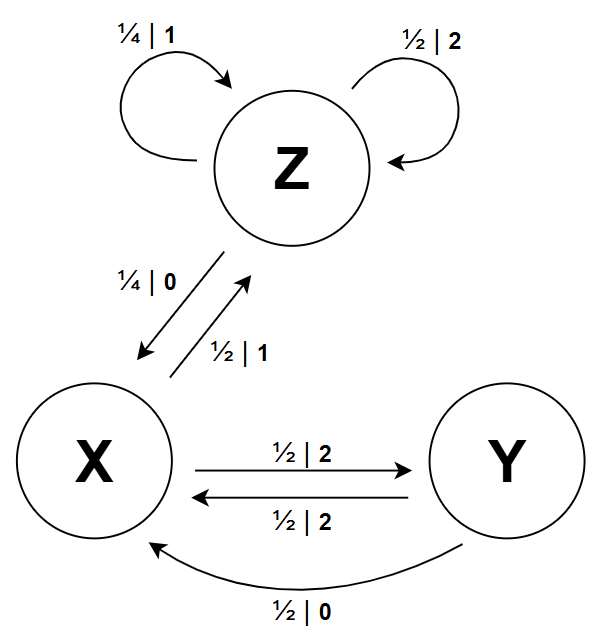
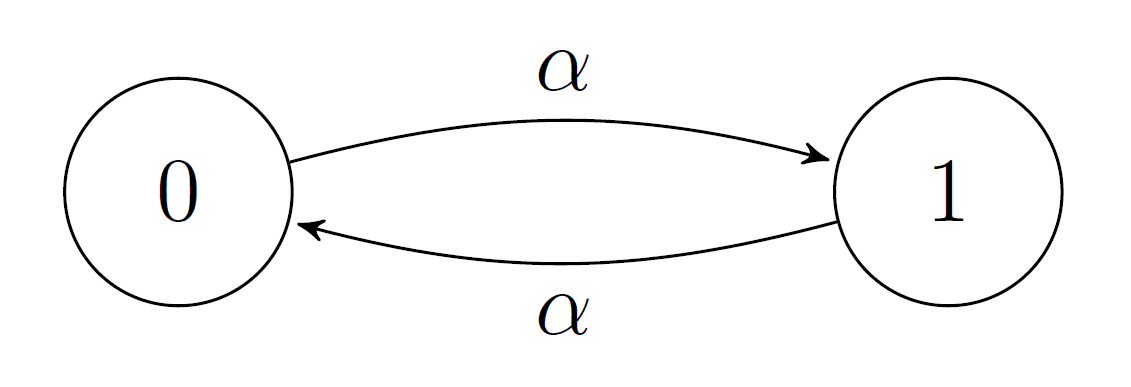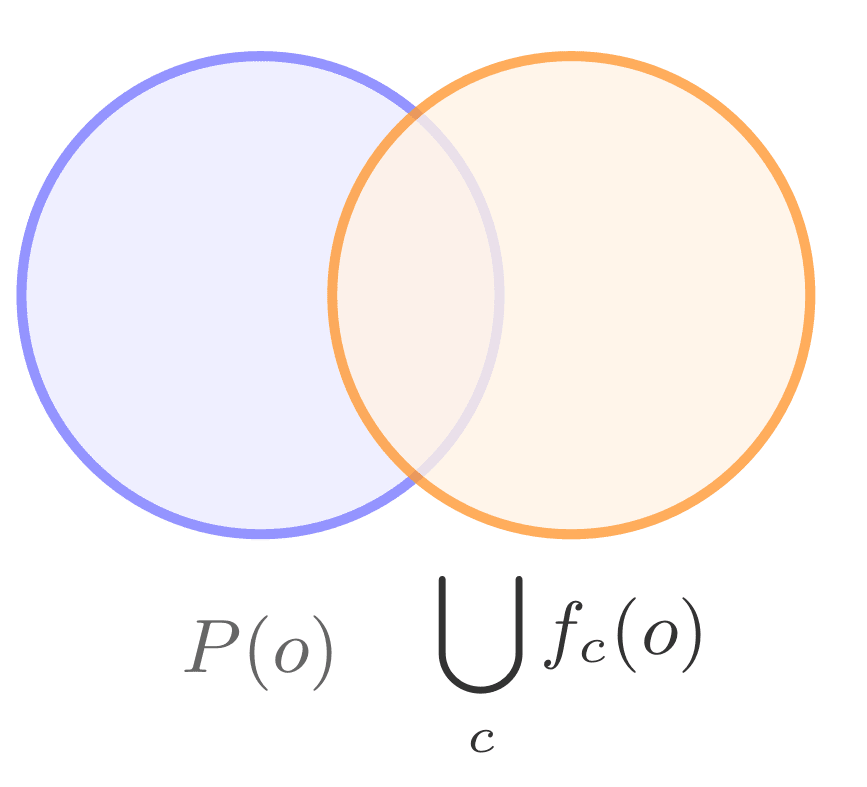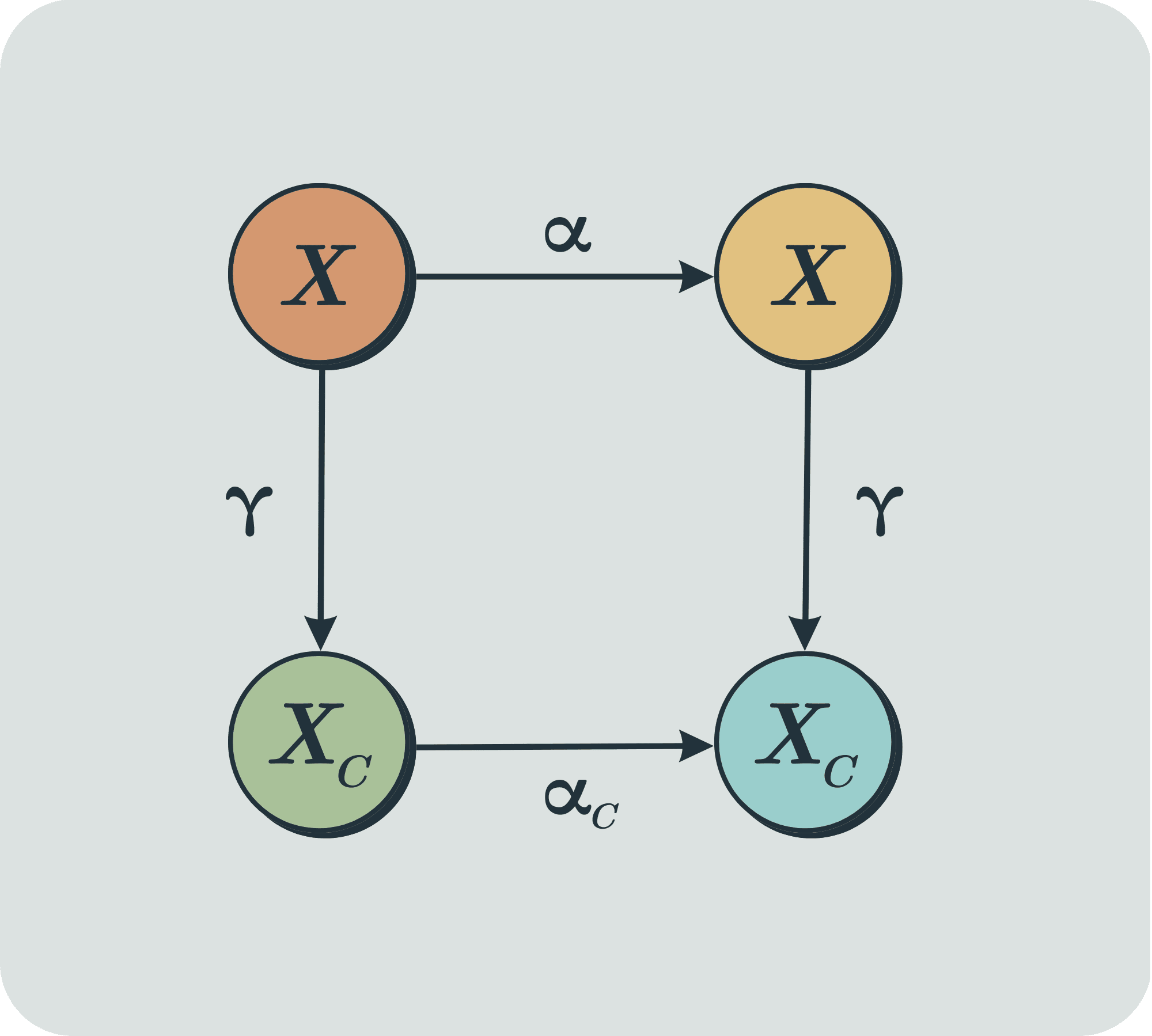This is a sequel to our previous post on the Touchette-Lloyd theorem. The previous post contained some introductory material and motivation for the theorem. Here, we will walk through the proof of the theorem and explore its applications in a few worked examples.
Funded by the Advanced Research + Invention Agency (ARIA) through project code MSAI-SE01-P005 This post was written during the Dovetail Research Fellowship. Thanks to Alex and Alfred for help during the writing process and to all the fellows for the fruitful discussions. I plan to share extended and more formal version of this post as Arxiv preprint, it will be linked here when its finished. ...
Part of what makes a system intelligent is its ability to analyze data generated by some process (for example, the past observations it might have made about the world) and use it to predict what data the process is likely to generate in the future (such as what it might observe in the future). So to understand how systems do this, it would be interesting to study the underlying mechanics of making accurate predictions about and discovering patterns in sequences of data. What is computational mechanics and why is it useful? Here is the informal definition...
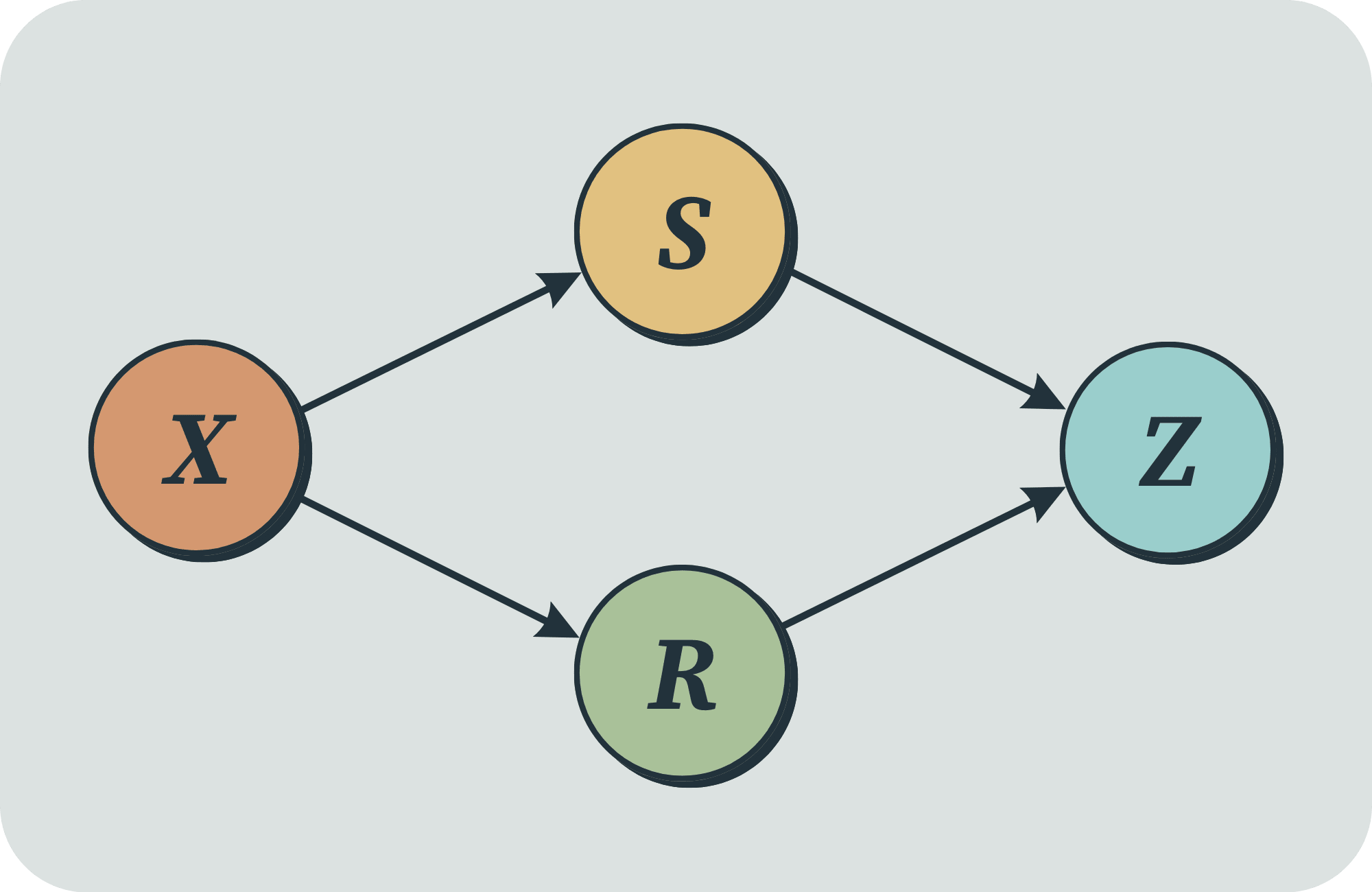
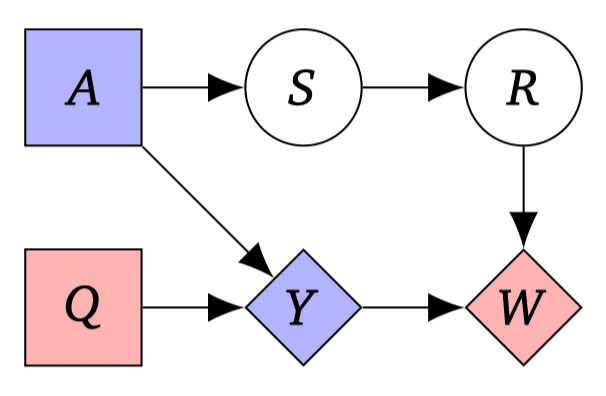
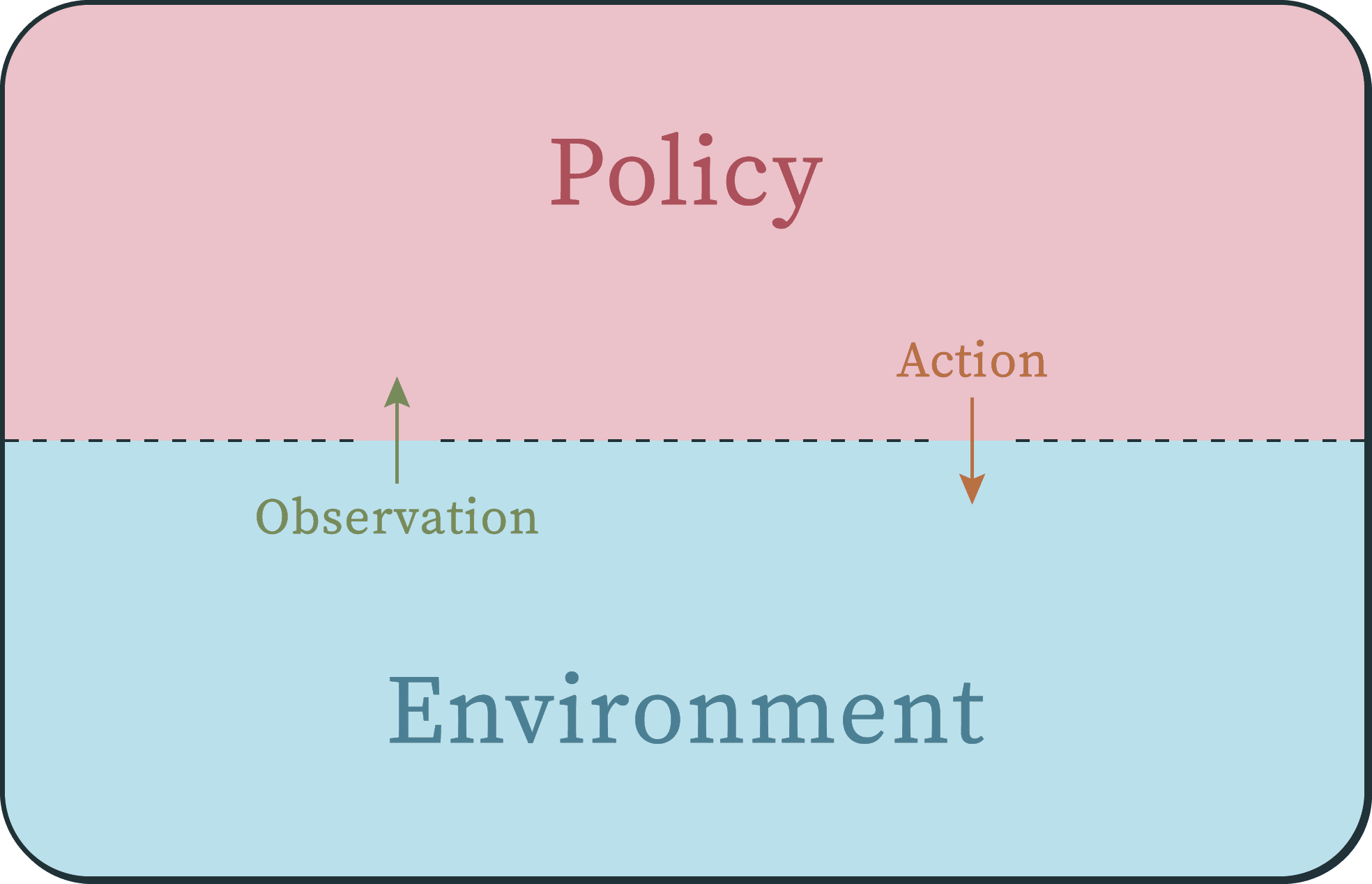
An important question in the field of AI is the extent to which successful behaviour requires an internal representation of the world. In this work, we quantify the amount of information an optimal policy provides about the underlying environment. We consider a Controlled Markov Process (CMP) with \\(n\\) states and \\(m\\) actions, assuming a uniform prior over the space of possible transition dynamics. We prove that observing a deterministic policy that is optimal for any non-constant reward function then conveys exactly \\(n \log m\\) bits of information about the environment. Specifically, we show that the mutual information between the environment and the optimal policy is \\(n \log m\\) bits. This bound holds across a broad class of objectives, including finite-horizon, infinite-horizon discounted, and time-averaged reward maximization. These findings provide a precise information-theoretic lower bound on the "implicit world model" necessary for optimality.
This post is an informal explainer of our paper which can be found on arxiv. This work was funded by the Advanced Research + Invention Agency (ARIA) Safeguarded AI Programme through project code MSAI-SE01-P005. Introduction There is an intuition that a powerful agent might have to contain some kind of world model as part of its structure in order to achieve its goals[1]. Part of this intuition...
We study AI agents through the lens of finite-state transducers and string-to-string behaviors. Instead of treating automata purely as language recognizers, we model agents as systems that map observation histories to action histories while interacting with an environment online. We introduce Finite-State Reactive Agents (FSRAs) as deterministic, finite-memory, reactive policies, establishing their equivalence to standard Mealy and Moore machines. Our main result (Theorem 3.13) characterizes exactly which behaviors can be implemented with finite internal state...
Tl;dr: This is the second post of two. The first post, An Ontology of Representations, argued that the convergence observed in neural network representations reflects shared training distributions and inductive biases rather than the discovery of objective, mind-independent structure. This post surveys the rapidly growing literature on using machine learning to (re)discover physical laws. I focus...
BLUF: The Platonic Representation Hypothesis, the Natural Abstraction Hypothesis, and the Universality Hypothesis all claim that sufficiently capable AI systems will converge on a shared, objective model of reality, and that this convergence makes alignment more tractable. I argue that this conclusion does not follow, for four reasons: Reduction between physical theories is not clean (Section...
This post was created during the Dovetail Research Fellowship. Thanks to Alex, Alfred, everyone who read and commented on the draft, and everyone else in the fellowship for their ideas and discussions. And thank you to Keerthana Kumaresan who created the images in this post. Overview The proof detailed in this post was motivated by a desire to take a step towards solving the agent structure...
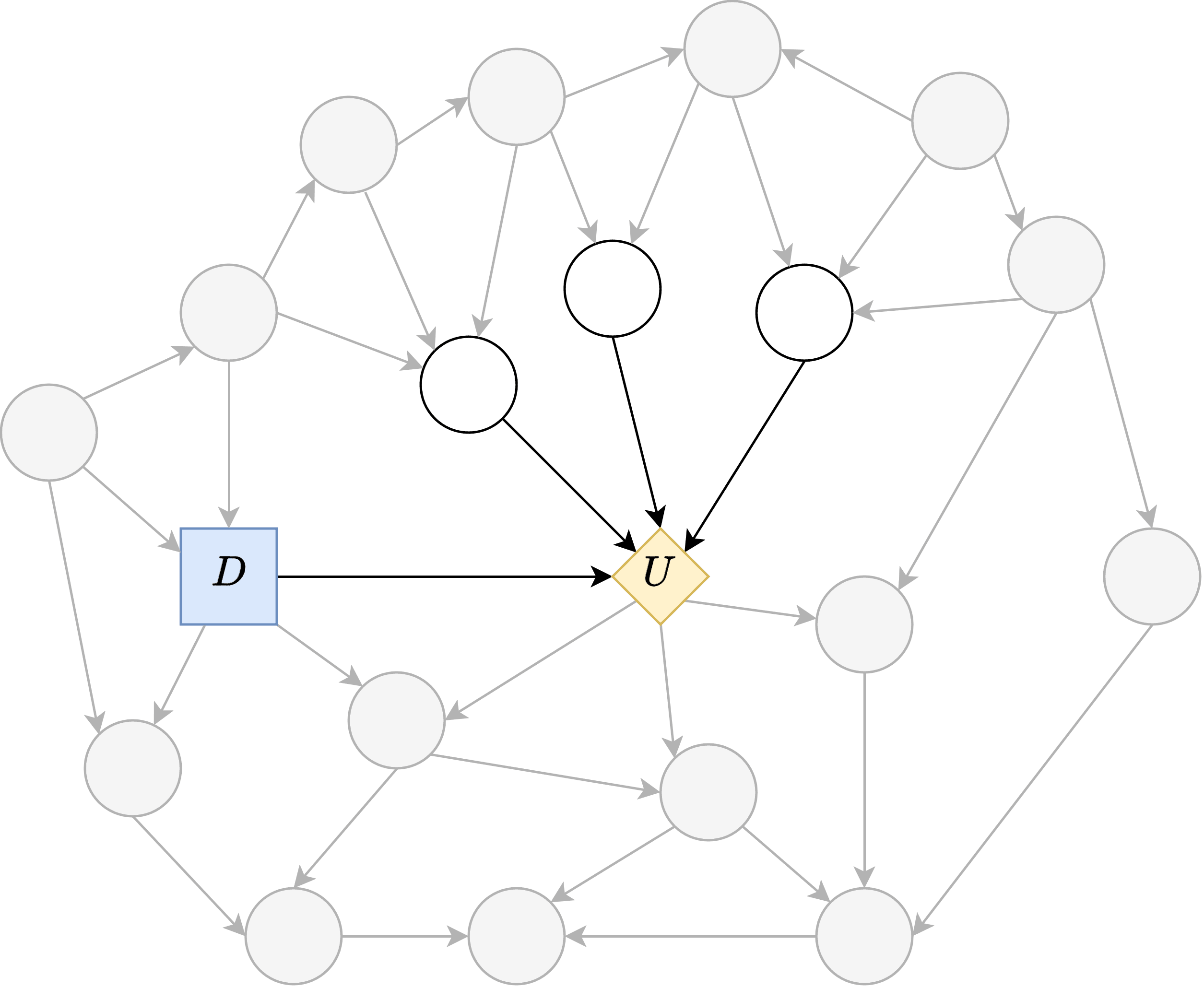
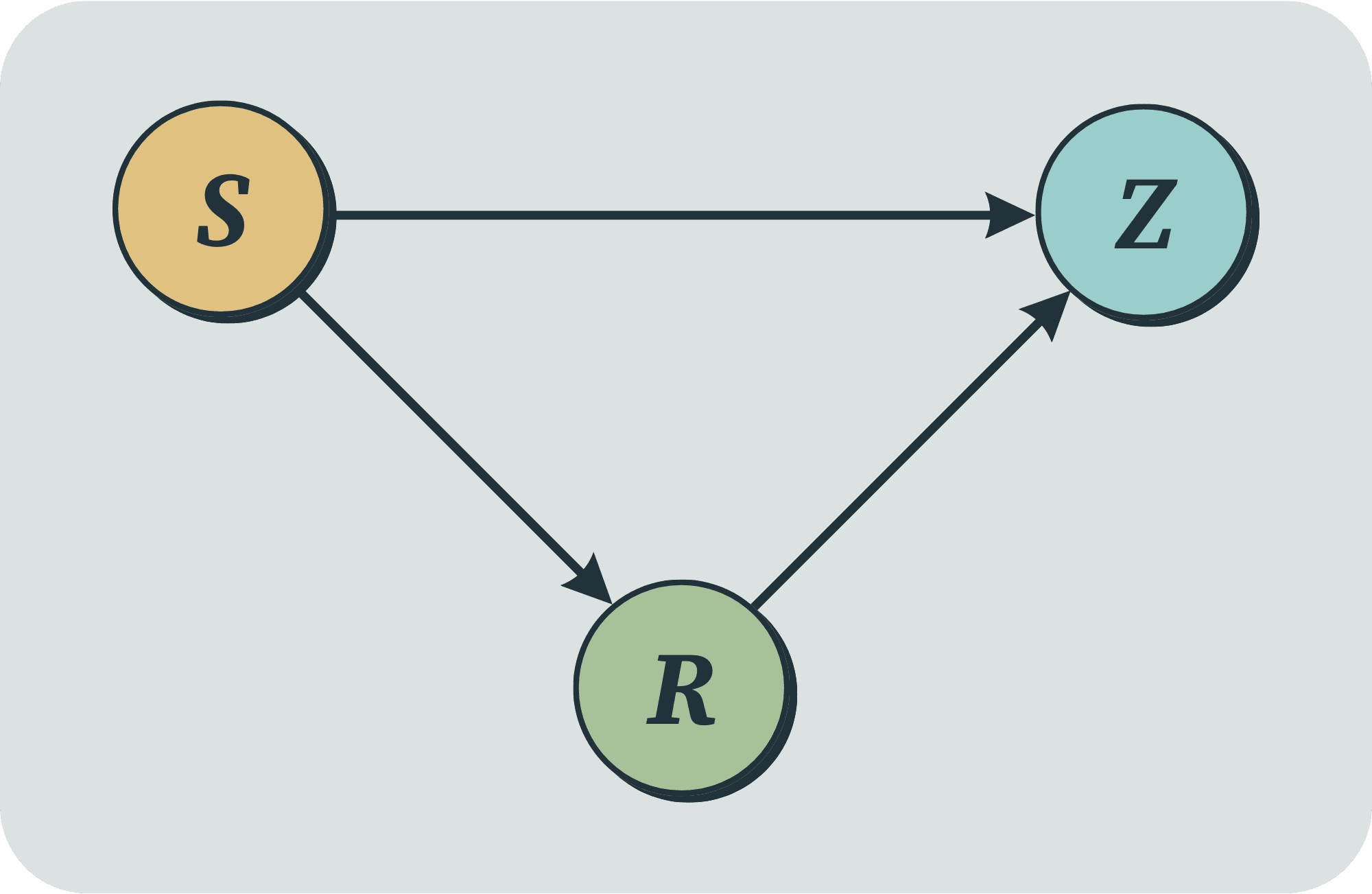
Deciding whether an agent possesses a model of its surrounding world is a fundamental step toward understanding its capabilities and limitations. In [10], it was shown that, within a particular framework, every almost optimal and general agent necessarily contains sufficient knowledge of its environment to allow an approximate reconstruction of it by querying the agent as a black box. This result relied on the assumptions that the agent is deterministic and that the environment is fully observable. In this work, we remove both assumptions by extending the theorem to stochastic agents operating in partially observable environments. Fundamentally, this shows that stochastic agents cannot avoid learning their environment through the usage of randomization. We also strengthen the result by weakening the notion of generality, proving that less powerful agents already contain a model of the world in which they operate.
The story so far We (Alfred and Jeremy) started a Dovetail project on Natural Latents in order to get some experience with the proofs. Originally we were going to take a crack at this bounty, but just before we got started John and David published a proof, closing the bounty. This proof involves a series of transformations that can take any stochastic latent, and transform it into a deterministic...
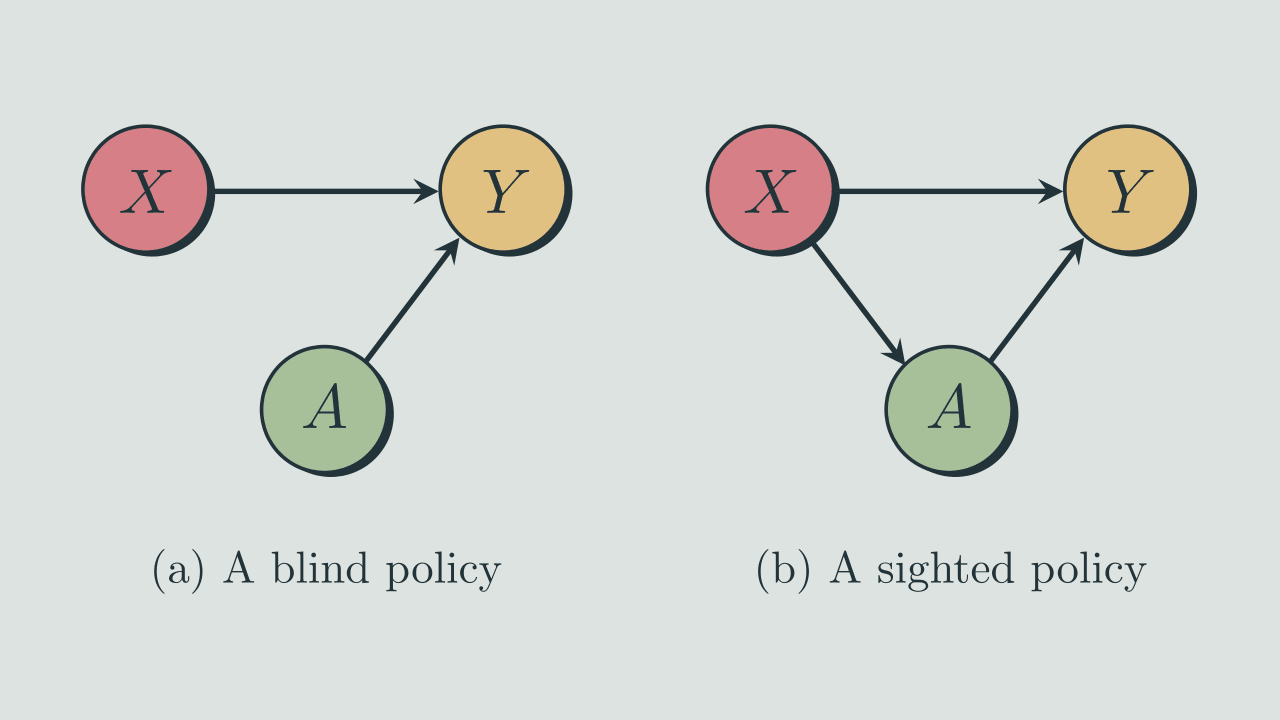
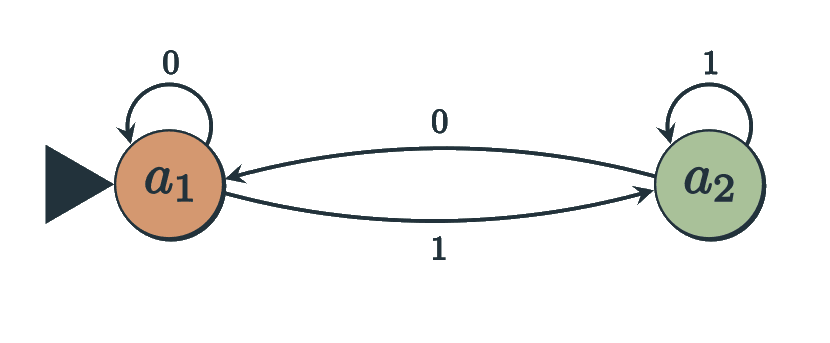
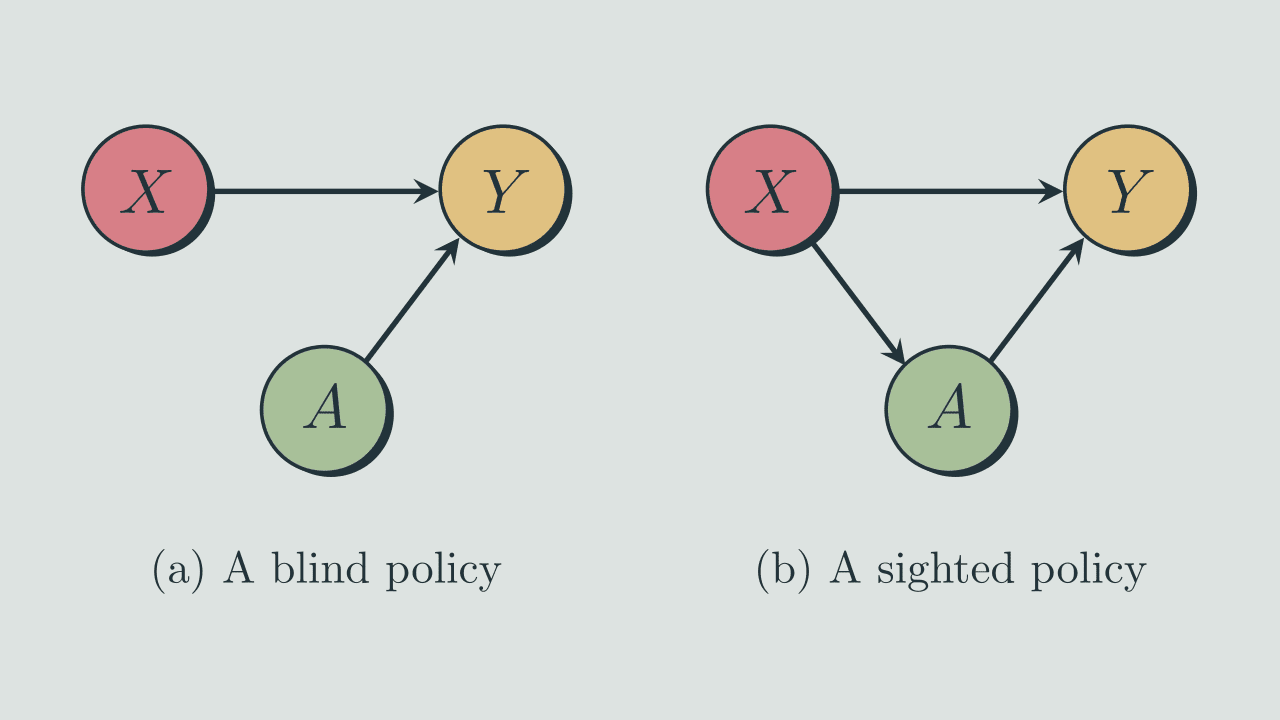
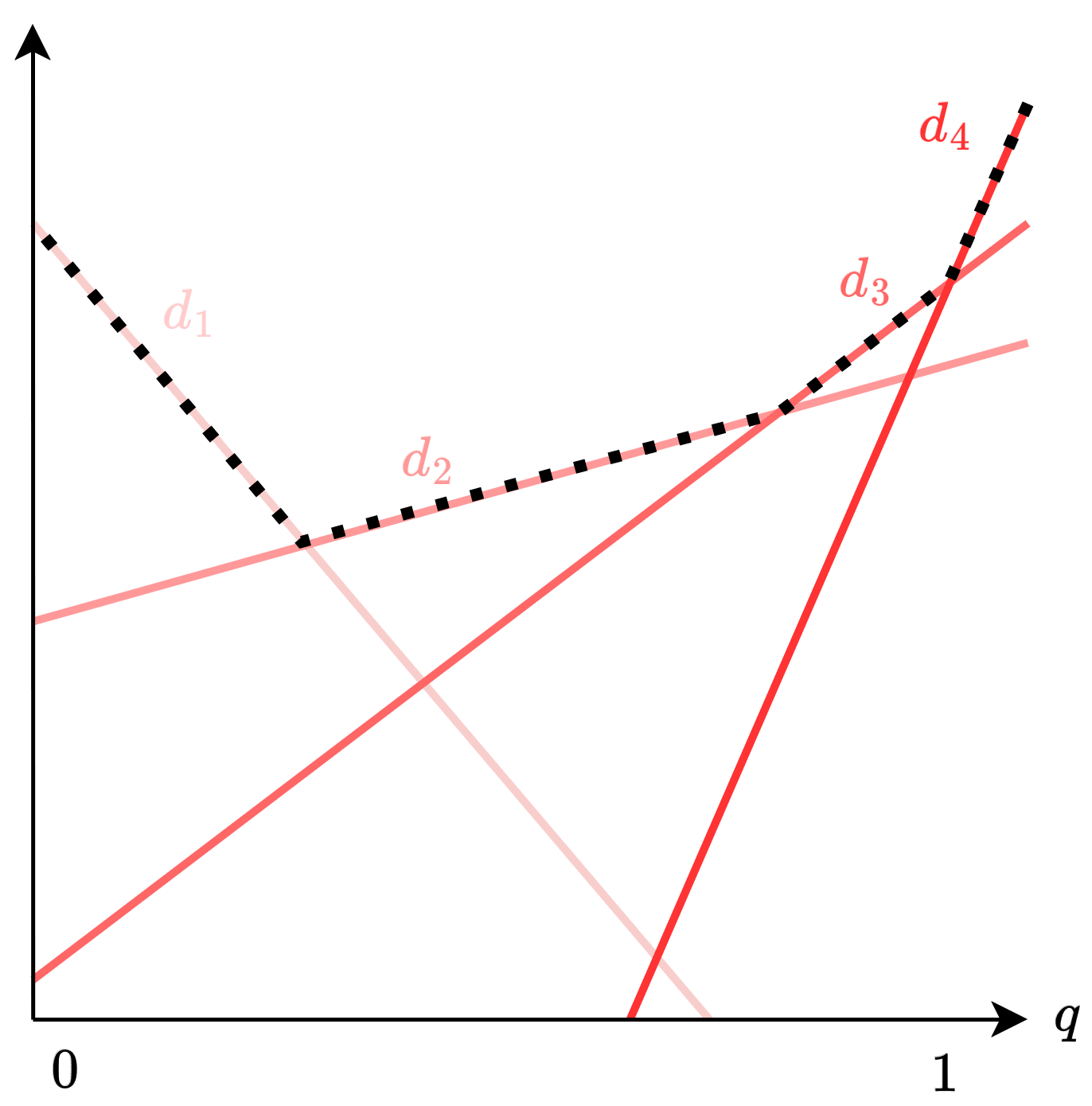
This post is about one of the results described in the 2004 paper 'Information-theoretic approach to the study of control systems' by Hugo Touchette and Seth Lloyd.[1] The paper compares 'open-loop' and 'closed-loop' controllers (which we here call 'blind' and 'sighted' policies) for the task of reducing entropy and quantifies the difference between them using the mutual information between the...
When studying for agent foundations research, I kept finding that I wanted a good general formalism of "stuff happening over time". Applications include...
The classical model of the scientific process is that its purpose is to find a theory that explains an observed phenomenon. Once you have any model whose outputs matches your observations, you have a valid candidate theory. Occam's razor says it should be simple. And if your theory can make correct predictions about observations that hadn't previously been made, then the theory is validated...
I was interested in the IMP because I wanted to know if it could be considered a selection theorem. A selection theorem is a result which tells us something about the structure of system, given that certain behaviours are selected for. In particular, in Agent Foundations, we are interested in circumstances under which 'agent-like structure' is selected for...
This post was written during the agent foundations fellowship with Alex Altair funded by the LTFF. Introduction This is the second part of a two posts series explaining the Internal Model Principle and how it might relate to AI Safety, particularly to Agent Foundations research. In the first post, we constructed a simplified version of IMP that was easier to understand and focused on building...
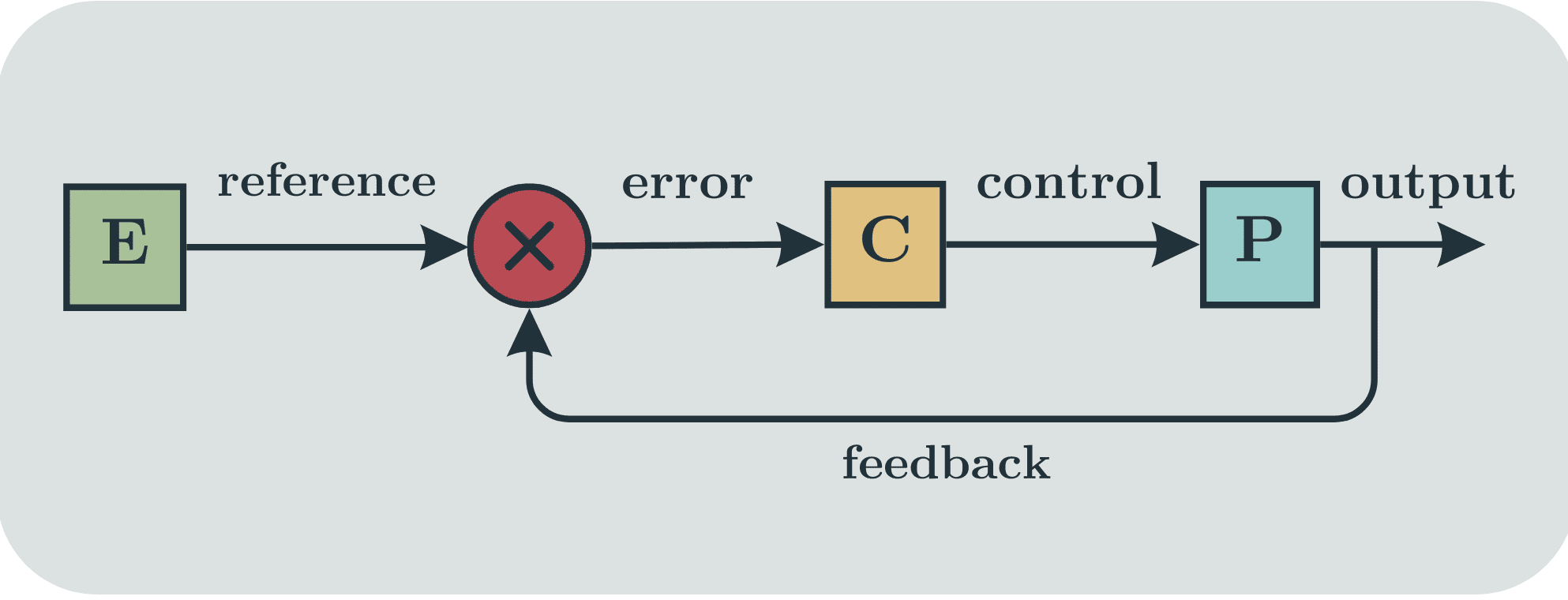
The Internal Model Principle (IMP) is often stated as "a feedback regulator must incorporate a dynamic model of its environment in its internal structure" which is one of those sentences where every word needs a footnote. I have written this post to summarise what I understand of the Internal Model Principle and I have tried to emphasise intuitive explanations.
This is the first part of a two-post series about the Internal Model Principle, which could be considered a selection theorem, and how it might relate to AI Safety, particularly to Agent Foundations research. In this first post, we will construct a simplified version of IMP that is easier to explain compared to the more general version and focus on the key ideas, building intuitions about the theorem's assumptions.
I am working on a project about ontology identification. I've found conversations to be a good way to discover inferential gaps when explaining ideas, so I'm experimenting with using dialogues as the main way of publishing progress during the fellowship. We can frame ontology identification as a robust bottleneck for a wide variety of problems in agent foundations & AI alignment...
When we have been discussing the Agent-like Structure problem, lookup tables often come up as a useful counter-example or intuition pump for how a system could exhibit agent-like behaviour without agent-like structure. It is fairly intuitive that, in the limit of a large number of entries, a lookup table requires a longer program to implement than a program which 'just' computes a function.
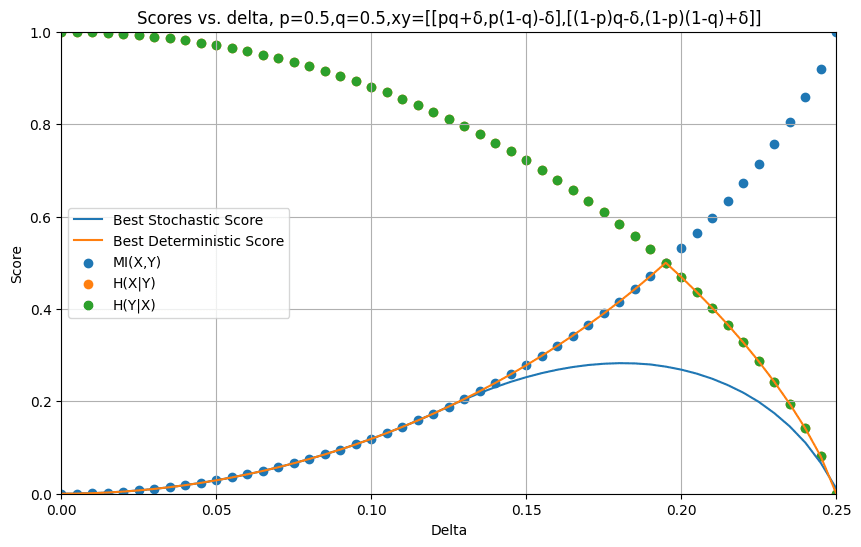
We prove a version of the Good Regulator Theorem for a regulator with imperfect knowledge of its environment aiming to minimize the entropy of an output.
This is a post explaining the proof of the paper "Robust Agents Learn Causal World Models" in detail. Check the previous post in the sequence for a higher-level summary and discussion of the paper, including an explanation of the basic setup (like terminologies and assumptions) which this post will assume from now on.
The selection theorems agenda aims to prove statements of the following form: "agents selected under criteria X has property Y," where Y are things such as world models, general purpose search, modularity, etc. We're going to focus on world models. But what is the intuition that makes us expect to be able to prove such things in the first place? Why expect world models?
The Good Regulator Theorem, as published by Conant and Ashby in their 1970 paper claims to show that 'every good regulator of a system must be a model of that system', though it is a subject of debate as to whether this is actually what the paper shows. It is a fairly simple mathematical result which is worth knowing about for people who care about agent foundations and selection theorems.
I think that the statement of the Natural Abstractions Hypothesis is not true and that whenever cognitive systems converge on using the same abstractions this is almost entirely due to similarities present in the systems themselves, rather than any fact about the world being 'naturally abstractable'. I tried to explain my view in a conversation and didn't do a very good job, so this is a second attempt.
A choice of variable in causal modeling is good if its causal effect is consistent across all the different ways of implementing it in terms of the low-level model. This notion can be made precise into a relation among causal models, giving us conditions as to when we can ground the causal meaning of high-level variables in terms of their low-level representations. A distillation of (Rubenstein, 2017).
This is an edited transcription of the final presentation I gave for the AI safety camp cohort of early 2024. It describes some of what the project is aiming for, and some motivation. Here's a link to the slides. See this post for a more detailed and technical overview of the problem. This is the presentation for the project that is described as "does sufficient optimization imply agent...
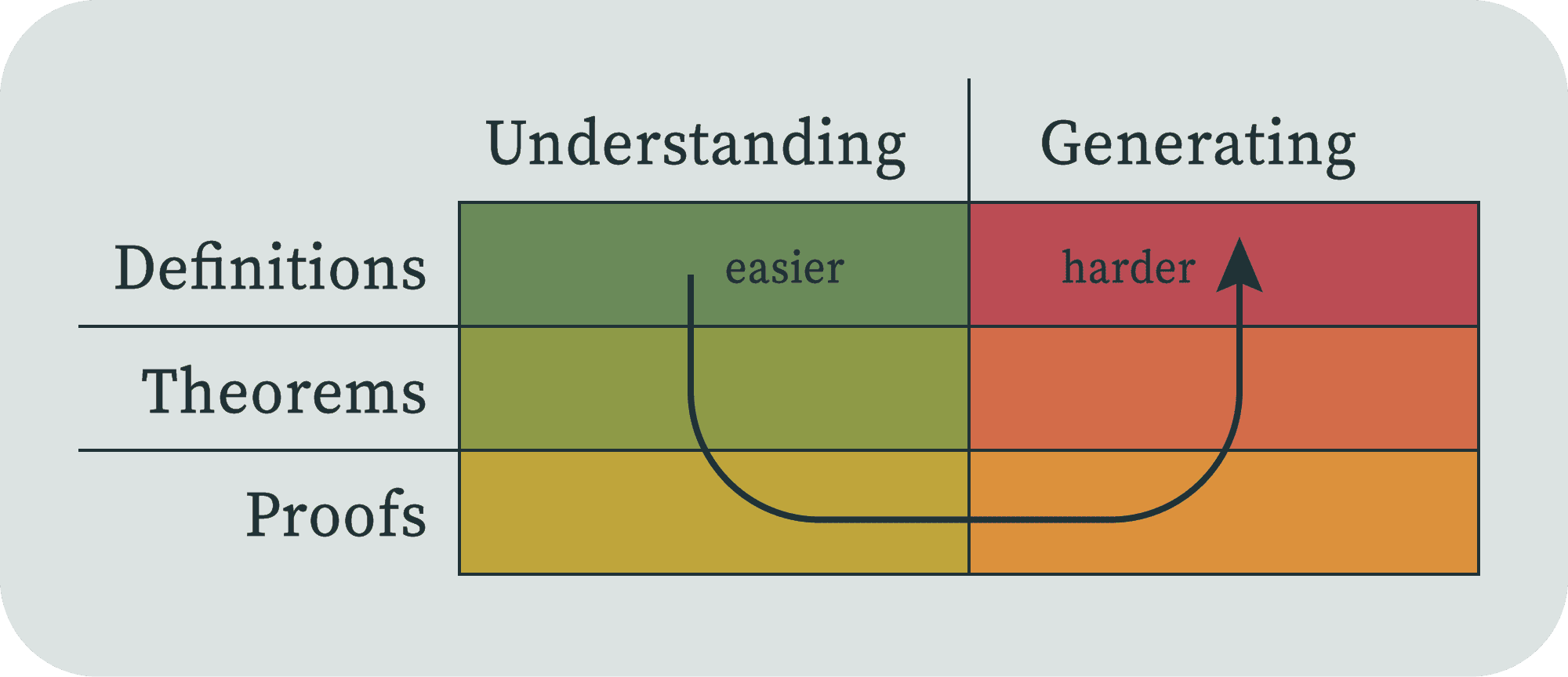
I've noticed that when trying to understand a math paper, there are a few different ways my skill level can be the blocker. Some of these ways line up with some typical levels of organization in math papers: Definitions: a formalization of the kind of objects we're even talking about. Theorems: propositions on what properties are true of these objects. Proofs: demonstrations that the theorems are...
In Clarifying the Agent-Like Structure Problem (2022), John Wentworth describes a hypothetical instance of what he calls a selection theorem. In Scott Garrabrant's words, the question is, does agent-like behavior imply agent-like architecture? That is, if we take some class of behaving things and apply a filter for agent-like behavior, do we end up selecting things with agent-like architecture...
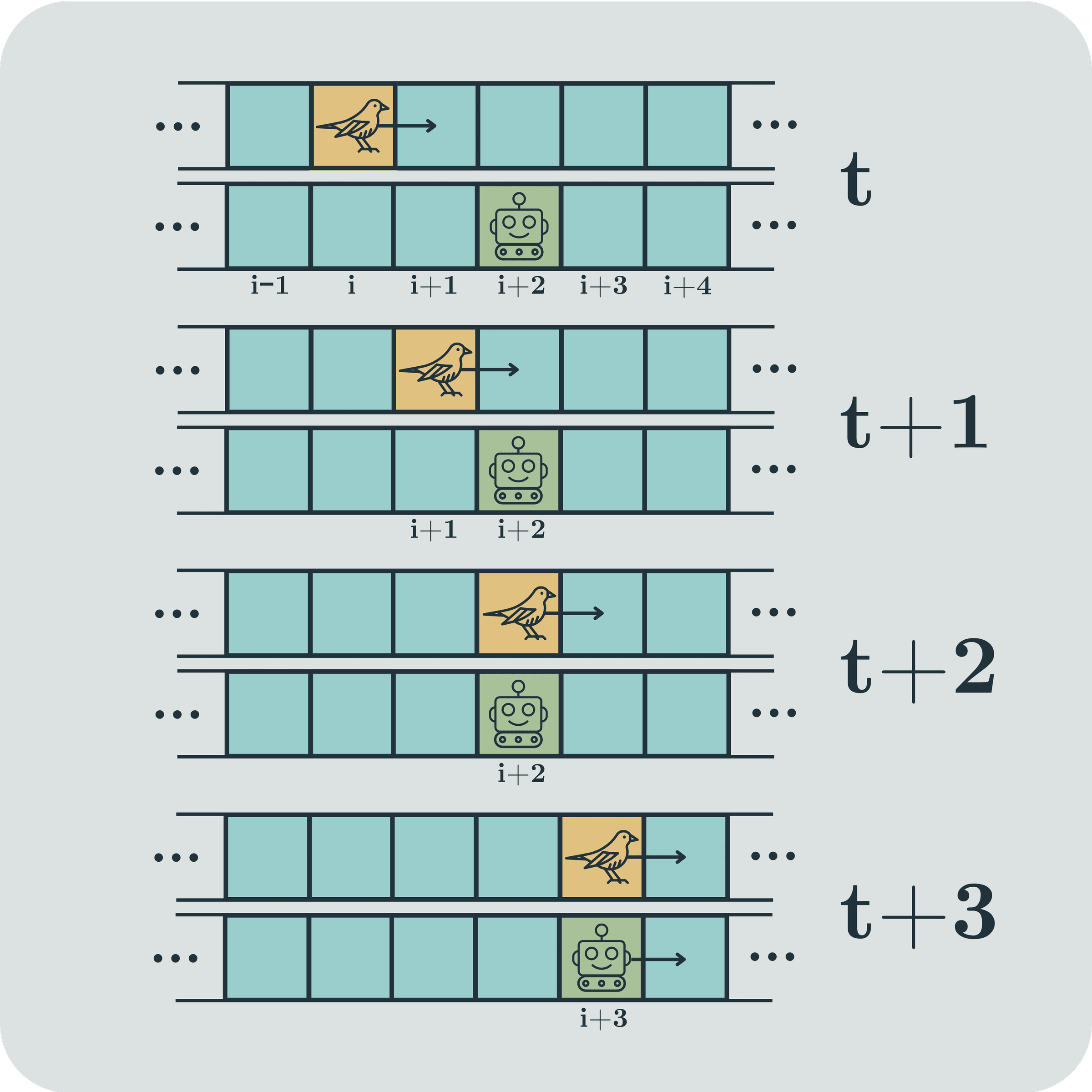
A major concession of the introduction post was limiting our treatment to finite sets of states. These are easier to reason about, and the math is usually cleaner, so it's a good place to start when trying to define and understand a concept. But infinities can be important. It seems quite plausible that our universe has infinitely many states, and it is frequently most convenient for even the...
In recent years, there have been several cases of alignment researchers using Conway's Game of Life as a research environment; Introducing SafeLife: Safety Benchmarks for Reinforcement Learning (Wainwright, Eckersley 2019) Agency in Conway’s Game of Life (Flint 2021) Finite Factored Sets (Garrabrant 2021) Optimization Concepts in the Game of Life (Krakovna, Kumar 2021) Finding gliders in the game...
Orienting around the ideas and conclusions involved with AI x-risk can be very difficult. The future possibilities can feel extreme and far-mode, even when we whole-heartedly affirm their plausibility. It helps me to remember that everything around me that feels normal and stable is itself the result of an optimization process that was, at the time, an outrageous black swan. Modernity If you were...
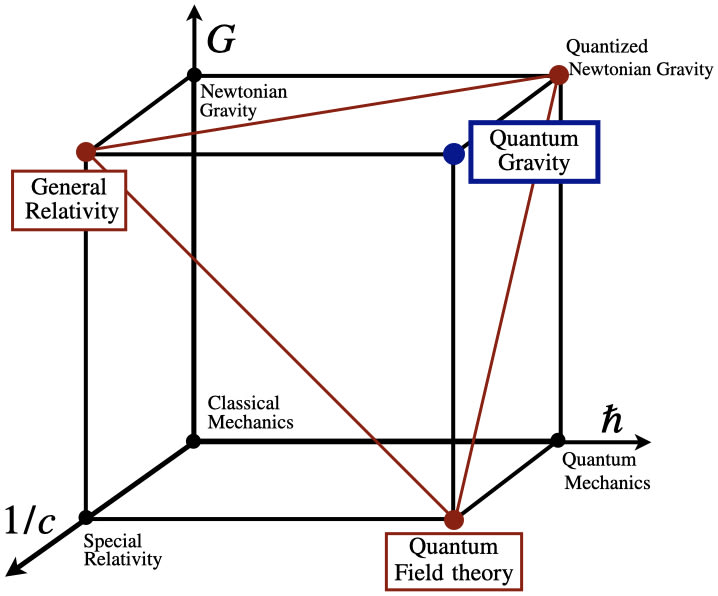
Explanations of entropy tend to only be concerned about the application of the concept in their particular sub-domain. Here, I try to take on the task of synthesizing the abstract concept of entropy, to show what's so deep about it. Entropy is so fundamental because it applies far beyond our own specific universe. It applies in any system with different states.